
クリップボードにコピーする方法はネットに数多く見つかりますが、クリップボードの内容を読み取る方法は意外に少ないと思ったことはないでしょうか。実は、過去からいくつかのブラウザーにクリップボードの読み取り機能が実装されたことがありました。ネットを検索するといくつかの方法が見つかりますが、動かないコードもちらほら。
実はクリップボードを扱う JavaScript API の仕様が過去に何度か作られては廃止となったこともあり、ブラウザーの実装もそれに巻き込まれてきたのが実情です。そしてネットの情報も、古い実装に基づいたものも数多く残っており、混乱のもとになっています。
今回は最新の仕様と実装に基づいて、クリップボードの内容の読み取り方法について詳しく紹介します。
クリップボードのテキストを読み取る
まずはクリップボードにコピーされたテキスト情報を読み取る方法から見ていきましょう。これは非常に簡単なコードで実現できます。次のコードでは、ボタンを押すと、クリップボードに保存されたテキストの内容をコンソールに出力します。
<button type="button" id="btn">Read</button>
document.getElementById('btn').addEventListener('click', async () => {
const text = await navigator.clipboard.readText();
console.log(text);
});
上記のボタンを押すと、まず Chrome の場合は次のような許可ダイアログをユーザーに表示します。ユーザーが許可すると、それ以降、そのサイトでは許可なしにクリップボードにアクセスすることができます。
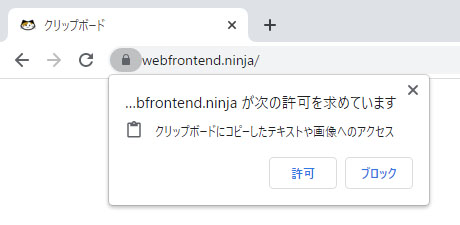
Safari の場合は、ボタンを押すと、そのボタンのそばに次のようなダイアログをユーザーに表示します。「ペースト」の部分をクリックすることで処理が進められます。しかし Chrome とは異なり、クリップボードの情報を読み取ろうとするたびにダイアログが表示されます。

クリップボードのテキストが無事に読み取れれば、コンソールにはそのテキストが出力されます。しかし、もしクリップボードにテキストが存在しない場合は、空文字列が出力されます。
では、JavaScript コードを 1 行ずつ見ていきましょう。まずは、navigator.clipboard.readText() です。この readText() メソッドは Promise オブジェクトを返します。そのため、前述のサンプルのように async の関数の中であれば、await で結果を受け取れます。
もし async の関数の中でなければ、次のように書くこともできます。
document.getElementById('btn').addEventListener('click', () => {
navigator.clipboard.readText().then((text) => {
console.log(text);
});
});
クリップボードの HTML を読み取る
クリップボードから HTML を読み取るって、どういうこと?と疑問に思ったかもしれません。まずは、どうやったら、クリップボードに HTML が保存されるのかを知らないといけませんね。
ブラウザーでウェブページを開き、そのページに記載されたテキストをコピーするのが一番分かりやすいでしょう。何かしらスタイルが適用されるテキストの場合は、プレーンテキストとして保存されるだけでなく、HTML コードとしても保存されることになります。
ではコードをご覧ください。
document.getElementById('btn').addEventListener('click', async () => {
// ClipboardItem オブジェクトのリストを取得
const items = await navigator.clipboard.read();
// ClipboardItem オブジェクトを一つずつ調べる
for (let i = 0; i < items.length; i++) {
// ClipboardItem オブジェクト
const item = items[i];
// データタイプが "text/html" のデータが存在するかをチェック
if (item.types.includes('text/html')) {
// Blob オブジェクトを取得
const blob = await item.getType('text/html');
// Blob オブジェクトから HTML テキストを取得
const html = await blob.text();
// HTML テキストを出力
console.log(html);
}
}
});
一気に複雑になりました。これを理解するには、クリップボードにはどのような形式でデータが保存されているのかを理解する必要があります。
たとえば、ウェブページ上のテキストをコピーしたとします。実は、クリップボードにはプレーンテキストが保存されるだけでなく、見た目をできる限り忠実に再現できるようインラインスタイルを盛り込んだ HTML コードとして保存されます。
こうすることによって、ペースト先がスタイルを再現できるなら HTML コードが、そうでなければプレーンテキスト情報がペーストされます。JavaScript では、どちらの情報にもアクセスできるようになっており、JavaScript 側で取捨選択してデータを扱う必要があります。
では、コードの詳細を見ていきましょう。まずは次の行から。
// ClipboardItem オブジェクトのリストを取得
const items = await navigator.clipboard.read();
ここでは read() メソッドを使っています。前述のクリップボードのテキストを読み取るサンプルコードでは readText() メソッドを使いましたが、ここではクリップボードのすべての情報を取得するため、read() メソッドを使う必要があります。
read() メソッドは、非同期に ClipboardItem オブジェクトのリストを取得します。なぜリストなのかというと、クリップボードには複数の値を保存できる場合があるからです。複数のテキストの同時選択は一部のアプリでしか使えませんので、あまり一般的ではないかもしれません。
実は Firefox が複数のテキストの同時選択をサポートしています。Firefox でウェブページを表示して、適当にテキストを選択状態にしてください。そして、Windows ならキーボードの Ctrl キーを押しながら、Mac なら Command キーを押しながら、マウスで別の箇所のテキストを選択してみてください。すると、先ほど選択した箇所は選択状態のままに 2 か所のテキストが選択状態になります。この状態で Ctrl + C を押せば、複数の箇所を同時にコピーできます。

前述の通り、複数のテキスト範囲を同時にコピーされた可能性を考慮し、HTML フォーマットのデータを取り出すためには、ClipboardItem オブジェクトのリストを走査します。
// ClipboardItem オブジェクトを一つずつ調べる
for (let i = 0; i < items.length; i++) {
// ClipboardItem オブジェクト
const item = items[i];
...
}
ただし、
上記のコードの中の変数 item が ClipboardItem オブジェクトを表しています。ほとんどのケースでは一つのテキストの範囲しかコピーされませんので、for 文を使ってリストを走査せず、ダイレクトに const item = items[0]; で ClipboardItem オブジェクトを抜き出してしまっても良いでしょう。
このオブジェクトがどんなフォーマットのデータを含んでいるのかを調べるには、ClipboardItem オブジェクトの types プロパティを見ます。
// データタイプが "text/html" のデータが存在するかをチェック
if (item.types.includes('text/html')) {
...
}
ClipboardItem オブジェクトの types プロパティは自身が保持しているデータのフォーマットを MIME タイプとして保持しています。しかし、複数のタイプを持つ場合がありますのでリストとして保持しています。
コピーデータに複数のフォーマットが存在するということに疑問を持った方もいらっしゃるでしょう。プレーンテキストをコピーした場合は確かにフォーマットは "text/plain" の 1 つしか持ち合わせません。しかし、ウェブページのテキストの場合、たとえプレーンテキストに見えたとしても、実際には何かしらのスタイルが適用されています。そのため、ウェブページのテキストをコピーすると、"text/plain" と "text/html" の 2 つのフォーマットを保持しているのです。
types プロパティは Array オブジェクトと同じですので、ここでは includes() メソッドを使って "text/html" の存在を確認します。
ClipboardItem オブジェクトに "text/html" のデータが含まれていることが分かったら、そのデータを ClipboardItem オブジェクトの getType() メソッドで取り出します。
// Blob オブジェクトを取得
const blob = await item.getType('text/html');
getType() メソッドは、引数に指定したフォーマット(MIME タイプ)に該当するデータを Blob オブジェクトとして非同期に取り出します。
Blob オブジェクトが取り出せたら、Blob オブジェクトの text() メソッドでテキストデータを抽出します。
// Blob オブジェクトから HTML テキストを取得
const html = await blob.text();
たとえば、Chrome でウェブページのテキストをコピーして、その内容を出力すると、次のようなデータになります。
<span style="color: rgb(67, 75, 100); font-family: Roboto, Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 300; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">JavaScript</span><!--EndFragment-->
実は単に “JavaScript” という文字列をコピーしただけなのですが、これほどの HTML スニペットが取り出せます。ブラウザーが可能な限り忠実にスタイルを保持するために頑張ったのが良く分かります。
ここではブラウザーでウェブページのテキストをコピーした場合を紹介しましたが、Word だろうが Excel だろうが、コピーされたものがテキスト情報であれば読み取れます。
クリップボードの画像を読み取る
クリップボードには画像も読み込めるのはご存知の通りです。ブラウザー上のページの画像であれば、マウスで右クリックして画像データをコピーできます。
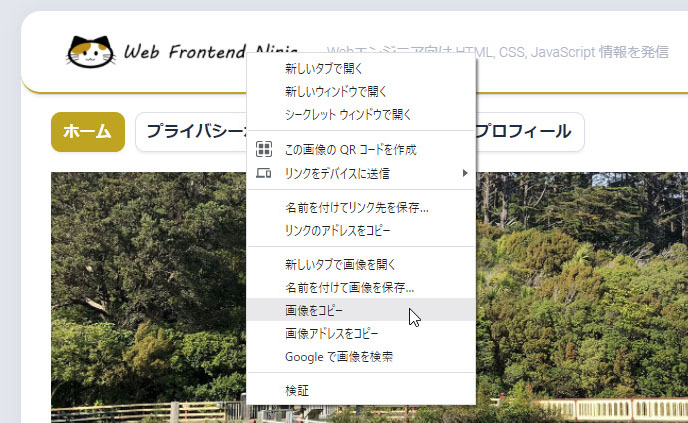
もちろん、JavaScript からクリップボード内の画像データを抜き出すこともできます。では、一気にコード全体を見てみましょう。
document.getElementById('btn').addEventListener('click', async () => {
// ClipboardItem オブジェクトのリストを取得
const items = await navigator.clipboard.read();
// ClipboardItem オブジェクトを一つずつ調べる
for (let i = 0; i < items.length; i++) {
// ClipboardItem オブジェクト
const item = items[i];
// データタイプが "image/png" のデータが存在するかをチェック
if (item.types.includes('image/png')) {
// Blob オブジェクトを取得
const blob = await item.getType('image/png');
// Blob オブジェクトを Data URL として読み取る
const reader = new FileReader();
reader.addEventListener('load', () => {
let img = document.createElement('img');
img.src = reader.result;
document.body.appendChild(img);
});
reader.readAsDataURL(blob);
}
}
});
ClipboardItem オブジェクトを取り出すところまでは、前述の HTML データを取り出すサンプルと同じです。ここでは、 ClipboardItem オブジェクトの types に "image/png" が含まれているかどうかをチェックする点が、前述のサンプルコードと異なります。
クリップボードにコピーされた画像データは Blob オブジェクトとして取り出せるのですが、ここでは、Blob オブジェクトから Data URL を読み取り、それを img 要素にセットして画面に表示しています。
ブラウザーのサポート状況
今回紹介した readText() メソッドと read() メソッドは、現時点では Chrome, Edge, Safari がサポートしています。
また、Firefox も実験的に実装しています。Firefox のアドレスバーに about:config と入力してフラグオプションを表示します。そして検索窓に asyncClipboard と入力すると、関連するフラグが列挙されます。
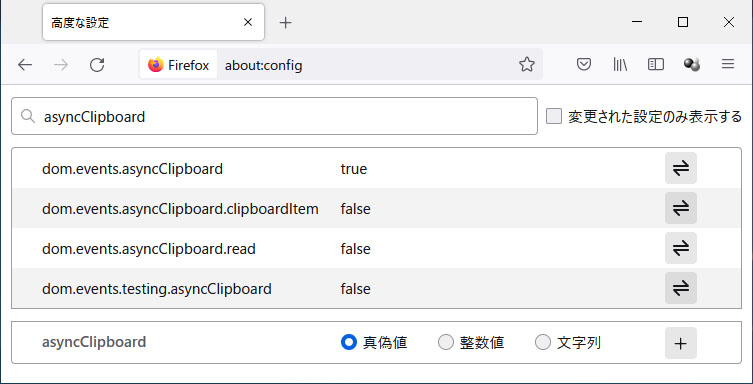
デフォルトでは上図の通りになっているはずです。3 つの項目で false がセットされていますが、これらを true に変更します。すると、これまで紹介したコードが動作するようになります。
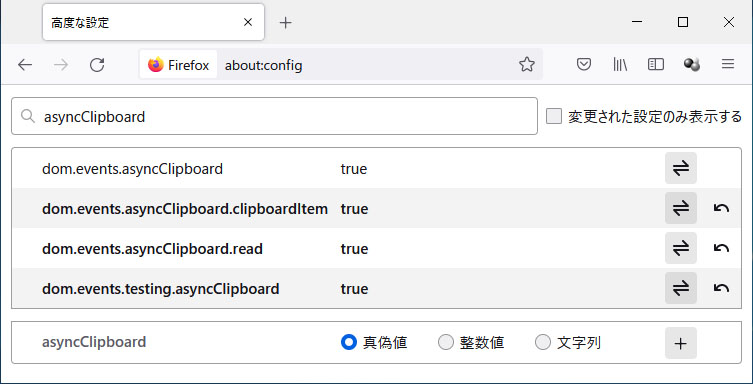
Firefox は実験的な実装ということもあり、ユーザー許可のダイアログを出さずにクリップボードにアクセスできます。
いずれにせよ、Chrome, Edge, Safari でサポートされていれば、実質的に日本では 90 % ほどのアクセスを占めることになりますので、クリップボードの読み取りを積極的に使いたくなります。ただし、標準化動向に関して不安要素もあります。
標準化動向とユーザー許可の仕様
今回紹介した JavaScript API は、W3C Clipboard API and events という仕様書にまとめられています。この仕様はまだ草案の段階です。これまでもクリップボード関連の API は標準化の過程で仕様が変更になることもありましたので、いまなお将来的に細かい点では相違が出るかもしれません。
実は、W3C Clipboard API and events 仕様では、クリップボードにアクセスするためには W3C Permissions API を使ってユーザーから許可してもらう必要があることになっています。しかし、前述の通り、Chromium 系ブラウザーも Safari も Permissions API を使わずにクリップボードにアクセスできます。
現時点で Safari は Permissions API を実装していませんが、Chromium 系ブラウザーは Permissions API を実装しています。そのため、W3C Clipboard API and events の仕様の通りにコードを書いても動作します。
document.getElementById('btn').addEventListener('click', async () => {
const permission = await navigator.permissions.query({
name: 'clipboard-read',
allowWithoutGesture: false
});
if (permission.state === 'granted') {
const text = await navigator.clipboard.readText();
console.log(text);
}
});
W3C では Permissions API も草案の状態です。そのため、将来的に Clipboard API を使うために Permissions API が必要なのかどうか、また、Permission API が必要になったとして将来的に上記のコードで動作するのかは分かりません。
Internet Explorer 11の場合
Internet Explorer 11もテキストに限りますがクリップボードデータを読み取ることができます。
document.getElementById('btn').addEventListener('click', function () {
const text = window.clipboardData.getData('text');
console.log(text);
});
前述の方法のような非同期なメソッドと違い、Internet Explorer 11の window.clipboardData.getData('text') は非同期ではありません。また、getData() メソッドの引数には "text" と "url" が指定可能です。
まとめ
W3C Clipboard API and events には今回紹介したこと以外にも、さまざまなクリップボード関連の機能が作成されています。ブラウザーの実装状況を見ながら、他の機能について紹介していく予定です。
今回は以上で終わりです。最後まで読んでくださりありがとうございました。それでは次回の記事までごきげんよう。
